
Regardless of your website’s size, the keys to a successful SEO campaign are (on-page), links (off-page), and technical factors.
Your content acts like the body of a race car, and it’s referring backlinks like race fuel. The technical factors act like the nuts and bolts allowing everything else to perform at its best.
If you miss either of these then your website will struggle to rank much like a race car struggling to get down the track.
In this case study, you’ll learn the exact steps that my team at The Search Initiative took to increase our client’s organic traffic by 96%. You will get a crash course in the three pillars of SEO (on-page, off-page, and technical factors) through the lens of this case study.

In this article, you’ll learn how to:
 Manage your crawl budget by fixing index bloat and ensuring your sitemap is implemented correctly to make it easier for Google to crawl and index the right pages.
Manage your crawl budget by fixing index bloat and ensuring your sitemap is implemented correctly to make it easier for Google to crawl and index the right pages.- Implement hreflang tags correctly to avoid potential duplicate content issues.
- Target long-tail keywords with supplementary blog content to improve keyword visibility and build topical relevance.
- Identify underperforming important pages that are lacking in backlinks to help build their authority and boost their rankings.
 Manage your crawl budget by fixing index bloat and ensuring your sitemap is implemented correctly to make it easier for Google to crawl and index the right pages.
Manage your crawl budget by fixing index bloat and ensuring your sitemap is implemented correctly to make it easier for Google to crawl and index the right pages.Before getting into the details of the strategy, here’s some important information about the website’s goals and the main challenges that were faced.
Table Of Contents
The Challenge
The main objective for this campaign was to increase the amount of quality organic traffic on the site to grow the number of leads.
The client is a US-based SaaS (Software as a Service) B2B company that builds and offers cloud software with web pages targeting a range of countries including English speaking countries such as the U.S.A., as well as Japan, China, Korea, and France.

With this in mind, one of the main challenges was index bloat. There were over 30k crawlable URLs on the English version of the website alone – quite excessive for a SaaS website. Fixing these crawl budget issues and uploading the XML sitemap which was missing when the client joined TSI was a priority. More on that, below…
The client’s hreflang (a way to tell Google about the language and target location of your content) setup had not been implemented correctly.
Although the core landing pages of the site were relatively well optimized, there was a lack of supporting content to drive traffic towards them. This is because the client’s blog was not active, with just a handful of articles published.

This was tackled by researching and writing informational blog articles to target long-tail keywords. This helped build the client’s topical relevance within the niche as well as provide internal linking opportunities towards the main pages on the site.
The final step was to build authority with a link-building strategy that focused on building page authority on the website’s most important pages: the homepage and service pages.
Follow the steps below and find out how you can also overcome these challenges for your own websites.
Crawl Budget Management
What Is Crawl Budget & Why Is It Important?
Google only has a limited amount of time and resources that it can allocate to crawling and indexing the World Wide Web. Therefore, Google sets a limit on how much time it spends crawling a given website – this is known as the crawl budget.

The crawl budget is determined by two elements:
- Crawl capacity limit – this is the maximum number of connections that Google can use to crawl your website at the same time. It’s there to prevent Googlebot from overwhelming your website’s server with too many requests.
- Crawl demand – Google calculates how much time it needs to crawl your website based on several factors like its “size, update frequency, page quality, and relevance, compared to other sites”.
 Crawl capacity limit – this is the maximum number of connections that Google can use to crawl your website at the same time. It’s there to prevent Googlebot from overwhelming your website’s server with too many requests.
Crawl capacity limit – this is the maximum number of connections that Google can use to crawl your website at the same time. It’s there to prevent Googlebot from overwhelming your website’s server with too many requests.If you have a large website with hundreds of thousands of pages, you’re going to want to make sure that only the most important pages are being crawled i.e. that you aren’t wasting your crawl budget on unimportant URLs.
Crawl budget management is about making sure that you’re stopping Google from crawling irrelevant pages that cause index bloat.
How To Fix Index Bloat
Index bloat occurs when Googlebot crawls too many pages of poor quality. These pages may offer little to no value to the user, be duplicated, be thin in content, or may no longer exist.

Too many unimportant and low-quality pages being crawled wastes precious crawl budget as Google spends time crawling those URLs instead of the important ones.
Our client’s English site had over 30k legacy event pages indexed – these were pages that included very little content about industry events within the client’s niche i.e. a flier for the event along with essential information such as dates and times.
Let’s look at some of the most common culprits that cause index bloat and how you can find them using a site search:
- HTTP pages – websites with SSL certificates that still have HTTP pages indexed cause unnecessary duplicate content. Use the following site searches on Google:
site:yourdomain.com inurl:http:// site:yourdomain.com -inurl:https://

- Pagination – likewise, paginated pages (where your content is divided across several pages) create needless duplicate content. To find them, use the following site searches on Google:
site:yourdomain.com inurl:/page/ site:yourdomain.come inurl:p=

- /tag/ pages – Tag pages are like category pages where you can group similar pages together. They’re commonly used to group similar blog posts i.e. example.com/tag/sports/.
Use the following site search to find /tag/ pages indexed on your site:
site:yourdomain.com inurl:/tag/

- /author/ pages – Author pages are similar to tag pages, except they are groups of pages written by the same author i.e. example.com/author/matt-diggity/
Use the following site search on Google to identify unnecessary /author/ pages:
site:yourdomain.com inurl:/author/

- and non-www. pages – another common culprit is having www pages crawled and indexed when you serve non www pages (and vice versa). To find these, use:
site:yourdomain.com inurl:www. site:yourdomain.com -inurl:www.

You may also come across these kinds of pages:
-
- Trailing slash – this is a problem if all of your URLs end with a trailing slash “/” but you have URLs without a trailing slash still indexed. For example:
example.com/with-trailing-slash/ example.com/without-trailing-slash
-
- Duplicate pages – if you have multiple pages containing the same content i.e. domain.com, domain.com/index.html, domain.com/homepage/ etc.
- Test/Dev pages – any pages from your staging site or development site should not be indexed. For example, dev.example.com or dev.example.com/category/sports/.
- Miscellaneous pages – i.e. checkout pages, thank you pages etc.
There are several ways to tell Google which pages you want crawled, and which ones you don’t:
-
- Robots.txt – Your robots.txt file is where you can specify any pages or resources that you do not want Googlebot to spend time crawling. Note that this file does not prevent Google from indexing the page – for this, you need to implement a noindex tag (next point).
 Robots.txt – Your robots.txt file is where you can specify any pages or resources that you do not want Googlebot to spend time crawling. Note that this file does not prevent Google from indexing the page – for this, you need to implement a noindex tag (next point).
Robots.txt – Your robots.txt file is where you can specify any pages or resources that you do not want Googlebot to spend time crawling. Note that this file does not prevent Google from indexing the page – for this, you need to implement a noindex tag (next point).Here’s the robots.txt file for my site:

You can generally find your robots.txt by accessing: yourdomain.com/robots.txt
The basic format for blocking Google from crawling your page(s) is:
User-agent: [user-agent name] Disallow: [URL string not to be crawled]
-
-
- User-agent – the name of the robot/crawler that should follow the rule, you can replace this with an asterisk (*) to set a catch-all rule for all robots.
- Disallow – this is the URL string that should not be crawled.
-
Here’s an example:
User-agent: * Disallow: /author/
The above rule prevents all robots from accessing any URL that contains /author/.
Find out more about the best practices for your robots.txt file here.
-
- Noindex tag – if you want to prevent Google from indexing a page, add a “noindex” meta tag within the <head> section of the page you don’t want indexed. It looks like this:
 Noindex tag – if you want to prevent Google from indexing a page, add a “noindex” meta tag within the <head> section of the page you don’t want indexed. It looks like this:
Noindex tag – if you want to prevent Google from indexing a page, add a “noindex” meta tag within the <head> section of the page you don’t want indexed. It looks like this:<meta name="robots" content="noindex">
If you have a WordPress website, you can do this easily via a plugin like Yoast SEO.

On any page, scroll to the Advanced tab on the plugin and where it says “Allow search engines to show this Post in search results?” select No.
-
- URL Removal Tool – The Removals tool on Google Search Console is another way to (temporarily) remove pages from Google’s index. Google recommends using this method for urgent cases where you need to quickly remove a page from Google Search.
 URL Removal Tool – The
URL Removal Tool – The 
Find out more about how to manage your crawl budget here.
XML Sitemaps
While your robots.txt file is used to prevent search engine bots from accessing certain pages, there’s another important file that you need to guide Google in the right direction regarding which pages you do want it to find and index.
That’s the XML sitemap – which our client happened to have missing from their website.
What Is An XML Sitemap & Why Is It Important?
The XML sitemap is a “map” of URLs using Extensible Markup Language.
Its purpose is to provide information about the content on your website i.e. the pages, videos, and other files, along with the respective relationships between them.

XML sitemaps are important because they allow you to specify your most important pages directly to Google.
Here’s an example of what a sitemap looks like: https://diggitymarketing.com/sitemap.xml

Providing this information makes it easier for crawlers like Google to improve crawl efficiency as well as understand the structure of your web pages. Think of it as a table of contents for your website.
By doing this, you’re increasing your chances of your web pages getting indexed more quickly.
Here’s an example of a basic XML sitemap:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://domain.com/</loc>
</url>
<url>
<loc>https://domain.com.com/blog/</loc>
</url>
</urlset>
More often than not, your XML sitemap will likely look like this auto-generated one from Yoast: https://lakewoodrestorationpro.com/page-sitemap.xml

Why? Because it’s much easier to use a plugin/tool to generate your sitemap than to hardcode it yourself manually.
How To Create An XML Sitemap
There are many ways to create an XML sitemap for your website depending on your CMS.
- Shopify, Wix and Squarespace – all automatically create your sitemap for you (which you can access at com/sitemap.xml) – but unfortunately, all of these are quite restrictive as you can’t make edits to them.
- WordPress – to create a sitemap for WordPress.org websites, I recommend using a plugin like Yoast – it’s free and really easy to use.
-
- Log into your WordPress dashboard and go to Plugins > Add New

-
- Search for “Yoast SEO” and press Install Now

-
- Then Activate

-
- Go to Yoast SEO > General > Features
 Go to Yoast SEO > General > Features
Go to Yoast SEO > General > Features
-
- Ensure the “XML sitemaps” option is set to “On”
 Ensure the “XML sitemaps” option is set to “On”
Ensure the “XML sitemaps” option is set to “On”
Your sitemap should now be automatically generated and available at either com/sitemap.xml or yourdomain.com/sitemap_index.xml
- No CMS / Any Website (Screaming Frog) – for any other website, you can use a site crawler like Screaming Frog to generate your XML sitemap. If your site has less than 500 pages, then you can use the free version – otherwise, you’ll need to upgrade to the paid version.
-
- Once you’ve installed and opened ScreamingFrog’s SEO Spider, Make sure Spider mode is selected.

-
- Enter your domain and click Start.

-
- The tool will crawl your pages and display a progress bar like this. Again, there’s a limit to 500 URLs, so if your site has more pages, you’ll need to purchase a license.

-
- Once your site has been crawled, go to Sitemaps > XML Sitemap in the top menu bar.

-
- Make sure 2xx response code is selected. If your site contains PDFs only include them if they are important and relevant.

-
- Go to the Images tab and select Include Images. The third box (Include only relevant Images with up to 10 inlinks) will automatically be checked. Click Export.
 Go to the Images tab and select Include Images. The third box (Include only relevant Images with up to 10 inlinks) will automatically be checked. Click Export.
Go to the Images tab and select Include Images. The third box (Include only relevant Images with up to 10 inlinks) will automatically be checked. Click Export.
Name your file “sitemap” it will be saved in .xml format.
There are also XML Sitemap generators like XML-Sitemaps.com where all you need to do is:
-
- Enter your domain and click START.

-
- The tool will crawl your pages and display a progress bar like this. Again, there’s a limit to 500 URLs, so if your site has more pages, you’ll need to upgrade to the paid version.

-
- Once it’s complete, click VIEW SITEMAP DETAILS.

-
- You can then download your generated sitemap by clicking DOWNLOAD YOUR XML SITEMAP FILE.

-
- You can also click VIEW FULL XML SITEMAP to preview the generated file in a new tab: https://www.xml-sitemaps.com/download/diggitymarketing.com-29b52add/sitemap.xml?view=1
One thing to note about the methods detailed above is that they may contain URLs or pages that you do not want to be included. For example, crawlers like Screaming Frog may include paginated pages or /tag/, /author/ pages – which as you learned above, cause index bloat. So, it’s always good practice to review the generated files and make sure that only the right pages are there.
There’s also the option to code your XML sitemap manually, this is fine for small websites with very few pages but perhaps not the most efficient for massive sites.
Regardless of which method you choose, remember to upload the sitemap.xml file to the public_html directory so that it will be accessible via domain.com/sitemap.xml.
How To Submit Your XML Sitemap To Google
To submit your XML Sitemap to Google, go to your Google Search Console and click Sitemaps > enter the location of your sitemap (i.e. “sitemap.xml”) > click Submit.

That’s it!
Remember to also add a link to your XML sitemap within your robots.txt file using the following directive:
Sitemap: http://www.example.com/sitemap.xml
If you have multiple sitemaps, simply add another directive, so you have something like this:
Sitemap: http://www.example.com/sitemap-1.xml Sitemap: http://www.example.com/sitemap-2.xml Sitemap: http://www.example.com/sitemap-3.xml
This final step makes it that extra bit easier for Google (and other crawlers) to find your sitemap and crawl your important pages.
Many plugins like Yoast automate this process for you, they’ll automatically add your sitemap into your robots.txt file.
Implementing hreflang Attributes Correctly
Implementing hreflang attributes correctly is an advanced technique that should only be done by experienced web developers, SEOs and those who understand the risks. However, if your website’s content is available in multiple languages, then the hreflang attribute is especially important for you.

If you set this up correctly, you could essentially clone your English website into different languages to maximize your traffic and keyword visibility across your target locations.
Now, I know not all of you will have websites that need to be translated into a range of languages. Don’t worry, there’s still something you can do to make this work for you.
Say you have a website in American English targeting the USA, you can then create a UK, Canada and Australian version of your site (which needs very little translation) to easily pick up more traffic within these regions. Read on to find an example of how to do this.
What Is hreflang?
Hreflang is an HTML attribute (or tag) used to tell Google about localized versions of your web pages. You can use this attribute to specify the language and target location of your content.
Why Is hreflang Important For SEO?

Hreflangs are important for SEO as they help search engines like Google to serve the most relevant version of your web pages based on the user’s location or preferred language. This improves the user experience of your website as it minimizes the chances of users leaving your website to find a more relevant result within their preferred language.
Correctly implementing hreflang tags has the added benefit of preventing duplicate content issues. Imagine you have two web pages that are written for British and American readers respectively.
- https://www.domain.com/uk/hreflang/ – written in British English (i.e. “optimise” and “£”)
- https://www.domain.com/us/hreflang/ – the same article as the above, but written in American English (i.e. “optimize” and “$”)
These pages are pretty much identical, but Google may see them as duplicates and thus prioritize one page over the other in its index.
Thus, implementing hreflang tags helps highlight the relationship between them: i.e. you’re telling Google that content on these pages is similar, but that they are both optimized for different audiences.

Here’s an example of a real-world site making great use of this by essentially “cloning” their website (with minimal translation) to target a number of English speaking locations.
- https://www.electricteeth.com/ – targeting American SERPs
- https://www.electricteeth.com/uk/ – targeting British SERPs
- https://www.electricteeth.com/ca/ – targeting Canadian SERPs
- https://www.electricteeth.com/au/ – targeting Australian SERPs
When Should You Implement A hreflang Attribute?
You should implement a hreflang attribute if:
- The main content on your web pages is in a single language, and you only translate parts of the template. For example, if your website is in English, and you only translate the menu bar and footer information of your pages to other languages.
- If your content has regional variations (i.e. content written in English, but targets different regions like the US and GB).
- If your entire website is fully translated into multiple languages. For instance, you have English and French versions of every single page on your site.
- If you want to expand your website (which you should) into one of the above configurations.
How To Implement hreflang Attributes Using HTML
The most common and simplest way to implement hreflang attributes is by using HTML statements.
All you need to do is add the following line of code to the <head> section of your web page:
<link rel="alternate" hreflang="x-y" href="https://domain.com/alternate-page"/>
For WordPress websites, you can add hreflang tags by updating your header.php file. To access this file, navigate to Appearance > Theme Editor, or use File Transfer Protocol (FTP).
Once you’ve opened the file, you can add the same line of code into the <head> section.

Let’s break this down:
-
- link rel=“alternate” – This tells Google that the link in the tag is an alternative version of the page that you’ve added the code to.
-
- hreflang=“x-y” – This tells Google why it’s an alternative version i.e. the content is in a different language where “x” is that language and “y” is the target locale.
- “x”: two-letter ISO 639-1 language code
- “y”: two-letter ISO 3166-1 alpha-2 region code which should be used when you want to target a specific locale of speakers i.e. “en-gb” for British English speakers and “en-us” for American English speakers.
-
- href=“https://example.com/alternate-page” – This tells Google the URL of the alternate version of the page.
Let’s go through an example using the following two pages again:
-
- British English: https://www.domain.com/uk/hreflang/
-
- American English: https://www.domain.com/us/hreflang/
The correct hreflang implementation for these pages would include adding the following code to the <head> section on each of the pages:
<link rel="alternate" hreflang="en-gb" href="https://www.domain.com/uk/hreflang/" /> <link rel="alternate" hreflang="en-us" href="https://www.domain.com/us/hreflang/" />
This method seems simple enough for the above setup, but what if later on you choose to translate the page into Danish and French?
You’d have to go through each page and add the additional lines of code:
<link rel="alternate" hreflang="da-dk" href="https://www.domain.com/dk/hreflang/" /> <link rel="alternate" hreflang="fr-fr" href="https://www.domain.com/fr/hreflang/" />
The final result in this example is that you have four unique pages each with their own respective language. Each of those four pages has all four hreflang attributes in their respective <head> sections.
You can use a plugin like Insert Headers and Footers to make this process easier. However, this is an advanced procedure and we recommend only experienced web developers and those who understand the risks implement this yourself. If you need any help implementing this, reach out to us at The Search Initiative.
How To Implement hreflang Attributes Using Your Sitemap
Another way to implement hreflang attributes is by using your XML sitemap.
This way’s a little tricker, but the great thing is that you can speed things up by using Erudite’s hreflang Sitemap tool to generate hreflang sitemap markups automatically.

But, if you’re interested in learning more about the how and why, read on:
To specify different variations of your content using your Sitemap, you need to:
-
- Add a <loc> element to specify a single URL.
-
- Then add a child <xhtml:link> attribute for every alternate version of your content.
Let’s see how this would look with our two example URLs:
-
- British English: https://www.domain.com/uk/hreflang/
-
- American English: https://www.domain.com/us/hreflang/
<url> <loc>https://www.domain.com/uk/hreflang/</loc> <xhtml:link rel="alternate" hreflang="en-uk" href="https://www.domain.com/uk/hreflang/" /> <xhtml:link rel="alternate" hreflang="en-us" href="https://www.domain.com/us/hreflang//" /> </url> <url> <loc>https://www.domain.com/us/hreflang/</loc> <xhtml:link rel="alternate" hreflang="en-us" href="https://www.domain.com/us/hreflang//" /> <xhtml:link rel="alternate" hreflang="en-uk" href="https://www.domain.com/uk/hreflang/" /> </url>
This may look more complicated than using just HTML, but if you have a large website with multiple versions of the same content in different languages, then instead of having to implement changes to each URL, you only have to update your XML sitemap.
Here’s an in depth guide on hreflang implementation if you’d like to learn more.
Best Practices & Common Pitfalls When Implementing Hreflang
Regardless of which method you choose, here’re some best practices and common pitfalls to avoid when implementing hreflang:
- Hreflangs are bidirectional, which means that if you add a hreflang from Page A (British English) to Page B (American English), then you must also add a hreflang from Page B (American English) back to Page A (British English).

If you don’t, Google will ignore the tags.
- Always remember to reference the page itself in addition to the translated variations. So, In addition to Page A (British English) pointing to Page B (American English), you should also add a hreflang from Page A (British English) referencing itself.

- Make sure you’re using valid language and locale
- Always use full URLs i.e. https://www.domain.com/uk/hreflang/ instead of domain.com/uk/hreflang/ or domain.com/uk/hreflang/
- Use the “x-default” tag (note that the “x” here is not a placeholder, this is the syntax you should use) to specify the page that you want to show when there is no other language variant that is appropriate. Here’s what it may look like:
<link rel="alternate" hreflang="x-default" href="https://www.domain.com/uk/hreflang" />
In this case, the default page that will be shown to users is: https://www.domain.com/uk/hreflang/
For more information on how to implement hreflang attributes, check out this detailed guide from Google.
Establishing Topical Relevance With Supporting Blog Content
If you have a website that sells fishing equipment, you probably want Google (and your readers, for that matter) to know that you’re expert fishers.
One way to do this is to create supporting blog content that allows you to showcase your expertise within your niche and build topical relevance. You also have the added benefit of targeting long-tail keywords that perhaps aren’t as competitive as the core keywords that you target on your primary pages.

For example, you may want to create guides on how to use certain pieces of equipment or create an ultimate guide on fishing in general.
This is something that our client was missing out on, as their blog section hadn’t been touched in a long time.
Finding Long-Tail Keyword Ideas
A great way to find long-tail keywords is via Ahrefs’ Keyword Explorer tool.
- Type a broad search term that is related to your niche into the Keyword Explorer, select your target location, and click on the magnifying glass.

- Scroll down and click any (or all) of the following options that offer various types of keyword ideas.

-
-
- Terms match – this will show you all of the related keywords containing all of the terms from your original keyword search within them.
- Questions – these are search queries phrased as questions – perfect for long-tail keywords that you may want to answer within a blog post.
- Also rank for – this report displays which other search terms the top 10 ranking pages for your original query are also ranking for.
- Also talk about – this report shows you which other keywords and phrases the top-ranking pages for your original query frequently mention.
-
In this example, we’ve used the “Questions” report to identify a potential topic that searchers might be asking about NFTs.
To find long-tail keywords that are relatively easy to rank for, filter the keyword list by:
-
-
- Using the “terms/parent topic” filter to narrow down the list for keywords based on specific phrases and words.
- Setting a maximum keyword difficulty e.g. if you have a new site with little to no links or topical authority, you might set KD to a max of 10. For more established and authoritative sites, you can go higher.
- Setting a minimum word count as long-tail keywords tend to have more words as they’re more specific
-

- Having identified the set of long-tail keywords (i.e. “how to create an nft on opensea”), you can now go ahead at creating a piece of content to target the term (more on that below). For example, you may write a blog article to answer this question in detail.
- To find more long-tail keywords, you can follow Steps 1 to 3 for the sub-topic, i.e., search using the Keyword Explorer tool for “opensea nft”.
With these long-tail keywords that are relevant to your niche, you’re solidifying your website’s topical authority within Google’s eyes.
Writing & Optimizing Blog Content
When it comes to writing the blog content, I highly recommend using Surfer’s Content Editor tool.
- Create your Surfer draft – Type in the primary keyword you want to target in the search bar, select the target location (in this case it’s “United States”) and click “Create Content Editor”.

You’ll then see a page that looks like this.

What the tool has done is analyze the length, the number of headings, the number of paragraphs, the number of images and most importantly, the common phrases and keywords used within the content of the top-ranking pages for your keyword.
-
- On the left-hand side, you’ll see a text editor – this is where you can write your content.
- On the right-hand side, you’ll see the results of Surfer SEO’s analysis. It provides suggestions on how long your content should be and how many headings and images to include. You’re also given a guide on how many times you should include a specific phrase or keyword within the main content based on the top-ranking competitors for your chosen keyword.
- Check the competition – Before you start writing your article, you should look at the content on the top ranking competing pages to inform your own heading structure and content plan for the article. You can do this by clicking on “BRIEF” and then opening the list of competitors.

Pay close attention to:
-
- The topics/headings that they cover – have they included FAQs?
- Any additional content – have they included images, videos or other forms of rich content?
- The tone and style of the article – is the content broken up into lists or blocks of text?
- Don’t focus on the score – As you add more content, your content score will increase (or decrease) depending on how your page fares against the competition. Just note that you don’t have to reach a perfect score of 100 (anything above 80 is considered good), the main goal is to ensure that you’ve covered the main topics that are expected of such an article and that the content is written in a way that is engaging for your audience.
- Don’t forget about internal linking – whilst writing your blog post, think about the internal linking strategy. This is a powerful way to guide the visitors who reach your website through the blog post to your most important landing pages.
Check out this video to learn more about how to interlink your pages together.
Building Links To Important Pages
One thing we noticed about the client’s backlink profile when they first joined was that many of the important service pages had little to no backlinks pointing to them which prevented those pages from ranking.
Let me break down how you can form a link-building strategy based on the above.
Identifying Link Building Opportunities Using Ahrefs’ Best by Links Report
Ahrefs’ Best by Links report is great for identifying which pages on your website have the most and least internal and external links.
- Enter your domain into Site Explorer

- In the left sidebar, find Pages > Best by Links

- Next, ensure that “External” is selected and that you filter the results so you’re only seeing pages that are live i.e. they aren’t redirected or return a 404 not found.
Also, sort the results in Ascending order based on Referring domains.

- Use the search feature to filter the results further by identifying particular types of pages that may be lacking in backlinks.
When looking through these results, identify any pages that are important to your website. These are most likely pages that appear in your main menu i.e. category pages for eCommerce websites or Service pages for SaaS websites.
Select pages that you know are targeting important keywords and are important for bringing in more revenue or conversions for your website. These are the pages that you primarily want to build links to.

You now have a list of important pages on your website with the least number of referring domains. Remember, these could be “money pages” as described above (i.e. category/service pages on your main menu), but you could also include blog posts that you feel are important in terms of their ability to rank for high volumes of keywords.
Once you’ve identified these pages, the next step is to start to build the actual links towards them to boost their page authority and rankability.
An effective tactic you can use is blogger outreach – here’re the main steps:
- Find Your Prospects – gather a list of potential websites that you don’t have backlinks from within your niche. A great way to do this is via Ahrefs’ Link Intersect tool which allows you to compare the referring domains to your site, with your competitors.

Looking at your competitors’ link profiles is a great place to start as they’ll already have links from topically relevant websites within your niche.
- Find Their Contact Details – once you’ve created your shortlist, find the contact information for the sites. This could be an email address to someone who works there or a general contact form. A great way to find email addresses is via tools like Hunter.io – download the Google Chrome extension and you’ll be able to grab this information at the click of a button!

- Craft Your Pitch – the pitch is arguably the most important part of the outreach process as it can make or break your chances of getting a link. Ensure that your pitches are personalized by adding relevant information about the website you’re pitching to. This may take longer to write, but you’re likely to have a higher response rate as a result.
Remember to keep your pitches short and concise:
-
- Explain who you are
- Why you’re contacting them
- What you have to offer
Here’s a template that you can use for your pitches:
Hello _____________,
My name is [your name] and I’m [what you do, who you are].
I really enjoyed [personalized sentence or two] in your article [the title of their page, linked to its
URL] which I came across while doing research on my own article about [your article title / topic].
But I noticed that you’re linking to this out of date page [URL of outdated article].
So I wanted to ask if my more up to date article might be worth a mention on your page: [add link to your article].
Either way, keep up the awesome work!
Look forward to hearing from you.
Best regards,
[Name]
- Send, Monitor & Repeat – once you’ve sent your pitches, it’s important to monitor your progress and experiment with subject lines and email copy to find out which ones yield the best results. This’ll allow you to streamline your process and scale it too.
Learn more about how to carry out blogger outreach in detail here.
The Results
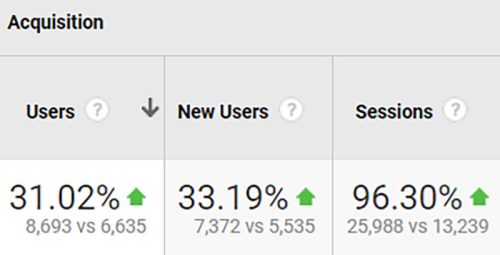
Here’s what we’ve achieved by executing the above strategies in just over six months.
When compared year-on-year, the organic traffic grew by 96%.


The graph below, which is taken from Ahrefs, shows the site’s keyword visibility within the top 10 positions of Google.
The number of keywords that the site is ranking for in the top 10 positions of Google increased from 259 keywords to 357 keywords a year later – an increase of 37.8%.

Conclusion
Without a technically sound foundation, the content you write and the links you build won’t be anywhere near as effective. You want to make it as easy as possible for Google to find and index the pages you want to be ranked – this is what technical SEO is all about.
In this case study, you’ve learned how to:
-
- Manage your crawl budget by identifying and removing unwanted pages from your index
- Create, publish and submit your XML sitemap to Google
- Correctly implement the hreflang attribute for websites that serve content in different languages/target locations.
- Build backlinks to pages that previously were lacking in link authority.
Implementing the above strategy will help ensure that the right pages make it into Google’s index so that you can maximize your visibility within the search results. Doing this can be pretty time-consuming, especially if you have a large website with thousands of pages.
If you’re looking for a team to take care of all of your SEO needs, get in touch with my team at The Search Initiative.
